
Dedicated Data Compression Engine for Improved Data Center Efficiency
Compression can help improve performance in the data center.
Compression is not a new concept, but as storage requirements grow it is becoming a more important tool in the data center. The goal of course is to encode information using fewer bits than the original data, therefore reducing the size of the data. Compute efficiency benefits also result as less data needs to be moved around.
There are two different types of compression:
1. Lossy, which is best suited for mp3, jpeg - typically used in audio or video streaming applications
2. Lossless, used for example in zip files - where all data must be available for the application use
With both types there are multiple compression techniques available. Some of the most common include:
• Match finding: In this technique, the algorithm looks for redundancies in a data set like a repeated string of bytes and stores a single copy of the redundant data. The amount of data is reduced by replacing the additional occurrences of the data string with references to the location of the stored copy to be read instead.
• Entropy coding: This technique finds patterns in seemingly arbitrary data sequences and assigns a symbol, or encodes a value, to represent the repeating pattern within the random data set. The size of the data is reduced by replacing the repeating pattern with a single value.
• Model compression: This advanced technique is targeted for machine learning models and AI applications requiring immense computational power and expensive high-speed GPUs to run. To transmit and process the complicated neural network algorithms on small, embedded systems, the machine learning models are compressed with by removing redundant neural network connections or bundling the neural network weights and biases into clusters, and in turn, reducing the total size of the data to be stored.
De-duplication, or dedup, like the match finding compression technique, removes duplicate copies of data so that only one copy is stored. It is typically used in the context of storage devices or at a system level in the data center, where you find a single copy of a shared file stored and the number of references to the copy is incremented each time the file is used by a different user. The advantage of dedup is that it can use the same match finding compression algorithm on large sets of data like an entire storage cluster for example and reduce the storage needs.
Many storage systems support both compression and dedup to maximize the storage capacity. In addition to storage capacity savings, compression improves system performance. The very basic principle is by writing less data, the data bus utilization increases, improving the write bandwidth and performance.
The compression ratio is the size of the uncompressed data divided by the size of the compressed data. Uncompressed data has a compression ratio of 1. The higher the compression ratio, the more compressed the data is. This is significant in SSD applications that utilize expensive Flash memory, due to the architecture involved in writing the data where a flash cell must be erased before it can be reprogrammed, and the nature of the media with the limited number of program and erase cycles available. In Flash operations, erasure can only occur on a block level, whereas programming is done on page level, leading to a larger portion of the flash getting erased and rewritten than needed for any new data. The portions of the flash that don’t need to be updated but are being erased to allow the incoming page write operation must be stored somewhere else, and all references to this data must be updated for future accesses. This multiplier effect of all writes to Flash storage on the SSD increases the ratio of actual Flash write operations to the ratio of incoming data write requests coming from the host from. The minimum this ratio is 1, and the higher the write amplification ratio is, the more program and erase cycles are initiated and depleting the overall endurance of the SSD. By compressing the original size of the data, the smaller sized data set can be stored in Flash with a less than 1 write amplification factor, requiring less program and erase cycles, and extending the SSD lifetime.
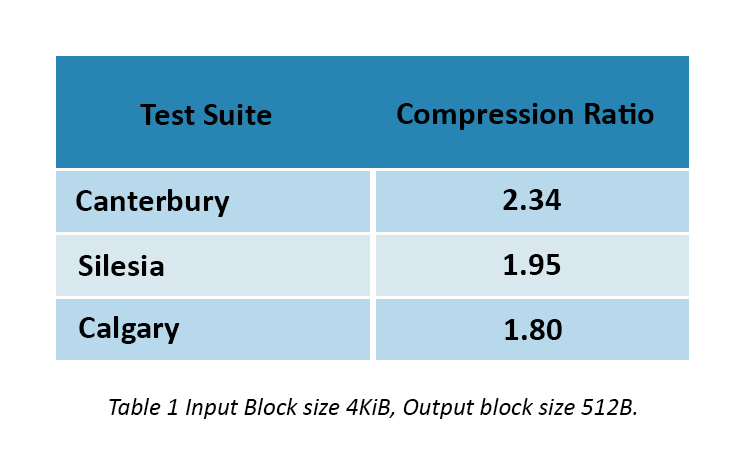
The most common compression test bodies, or corpus, that benchmark compression ratios and performances are the Calgary corpus, the Canterbury corpus and the Silesia corpus. Silesia is the latest, which utilizes updated data sets that cover today’s use cases. The attached table illustrates the PCIe Gen-4 Flashtec NVMe3016 enterprise NVMe SSD controller performance under the tests.
The compression ratio is achieved via a dedicated compression engine that is compliant with the Deflate Compressed Data Format Specification (RFC-1951) for lossless algorithms, with a simplified internal format (zlib).
• The data format is block based, with padding if unaligned
• Compressed and uncompressed data block size is configurable at 32B-8KB, and up to 64KB with SGL
Coupled with a SHA-256 Hash engine, high CPU processing power, and the advanced flexible and programmable architecture of the NVMe3106 controller, users can customize their SSD firmware to use the various hardware knobs to implement the most efficient compression schemes for their application needs.
As an industry leading enablement solution for the enterprise NVMe SSD controller market, the Flashtec NVMe3016 NVMe SSD controller enables innovative storage solutions which deliver high performance with low-cost and power efficiency based on a highly flexible and programmable controller platform. Hardware compression is just one of the many capabilities that make Flashtec® products the right solution for enterprise NVMe SSDs for data centers of the future.
For more information, visit https://www.microchip.com/en-us/products/storage/flashtec-nvme-controllers.