VectorBlox™ Accelerator SDK 2.0: AI/ML Inference for PolarFire® FPGAs and SoCs
Why FPGA Designers Choose VectorBlox Accelerator
- Software-based implementation allows AI deployment without reprogramming the FPGA
- Power efficiency that delivers < 5W inference and video pipeline
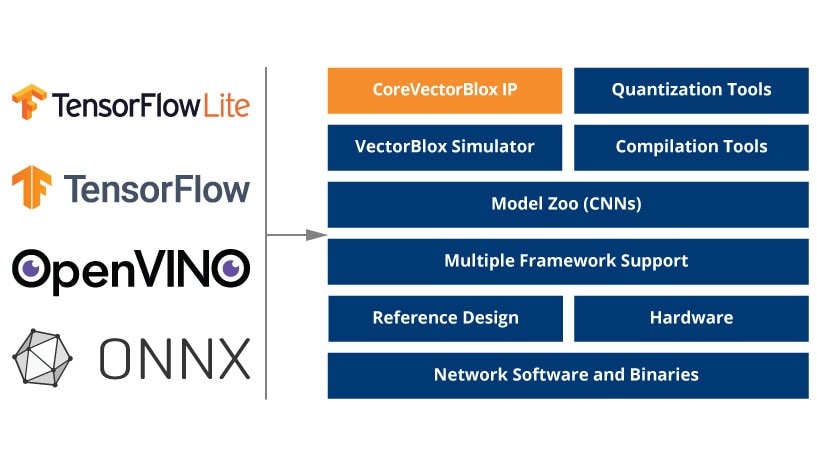
- Seamless AI model integration that supports TensorFlow®, TensorFlow Lite, ONNX and OpenVINO®
- Fast prototyping and quick evaluation with pre-optimized CNNs and simulation tools
- Configurability that prioritizes performance and low power consumption
Step 1: Install VectorBlox Accelerator
Install the VectorBlox™ SDK and read the Programmer’s Guide.
Step 2: Convert Your CNN
Convert your CNN using one of the tutorial scripts found in our tutorials section. If you have successfully converted your CNN without any errors, proceed to the next step; otherwise, reach out to us.
Step 3: Procure the Kit
PolarFire SoC FPGA is supported by VectorBlox SDK 2.0. To get started quickly, purchase the PolarFire SoC Video Kit and visit the video kit demo on GitHub.
Step 4: Install Libero® SoC Design Suite
If you want to view the reference design or rebuild its components, you must install the Libero SoC Design Suite.
Step 5: Merge
Click on the “Request Free License” link below to generate the free Libero SoC Design Suite Silver and CoreVectorBlox licenses. Then merge the two licenses*.
*Refer to section 7.3 of the Libero software quick-start guide to learn how to merge these licenses.
- The CoreVectorBlox IP
- Demo Flow
- Reference Design on the PolarFire SoC Video Kit
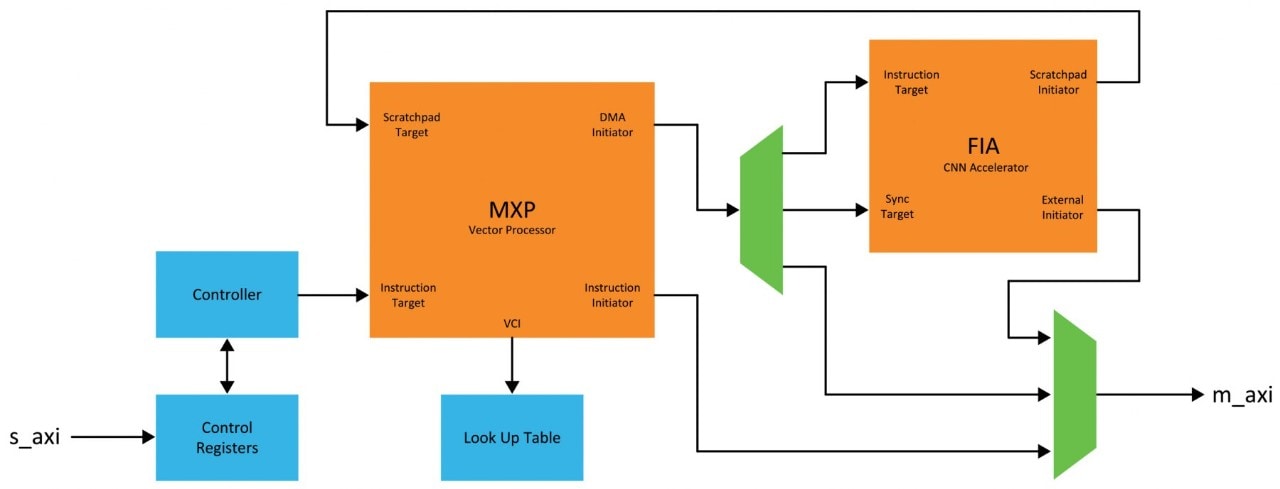
Features of the CoreVectorBlox IP
- Multiple size configuration
- Overlay design that allows multiple networks to run on the same core and switch dynamically
- Configurable width (64b to 256b) AXI4 memory master for data access
- AXI4-Lite device for control and status
- Memory based with the ability to read inputs from memory-mapped master and write outputs
- Internal vector processor for general neural networks
- CNN accelerator for convolutional layers
The VectorBlox™ SDK consists of framework-dependent quantization tools that convert FP32 representations into INT8 and a compilation tool that generates binaries and weights. These tools are stored in nonvolatile memory, typically SPI Flash, and loaded into DDR memory when the SoC FPGA is turned on.

The PolarFire SoC Video Kit is designed to evaluate the VectorBlox SDK. It includes a preconfigured reference design with a MIPI CSI-2®-based camera interface, an HDMI® input, Image Signal Processing (ISP) pipeline, the VectorBlox SDK AI engine and an HDMI output for displaying results on a monitor.

Unlock the power of AI with our VectorBlox 2.0 SDK on PolarFire SoC FPGAs. We will explore AI use cases, dive into SDK capabilities and share best-in-class efficiency and reliability.

PolarFire FPGA Ethernet Sensor Bridge for NVIDIA® Holoscan
Seamlessly integrating high-speed sensor data with NVIDIA's AI-driven Holoscan platform, our Ethernet sensor bridge for NVIDIA Holoscan is an essential solution for industries that use AI. This bridge enables advanced imaging capabilities in medical, industrial, automotive and other sectors.
In healthcare, NVIDIA Holoscan enhances medical imaging and robotic surgery by processing sensor data quickly for accurate diagnostics and interventions. The low-latency communication of the Ethernet sensor bridge allows cloud AI computations closer to data sources, improving system responsiveness and efficiency.